

Introduction
I often answer questions on Istio’s GitHub Discussions, and recently, I came across a discussion about Istio’s primary-remote deployment, specifically regarding how the remote cluster’s gateway initially authenticates to an external Istiod instance. This issue touches upon the core security mechanisms of service meshes in multi-cluster configurations, which I think merits more in-depth sharing in the community.
In the official Istio documentation on Installing Primary-Remote on different networks, one of the steps is to attach cluster2 as a remote cluster of cluster1. This process creates a Secret containing a kubeconfig configuration, which includes the certificates and tokens required to access the remote cluster (cluster2).
# This file is autogenerated, do not edit.
apiVersion: v1
kind: Secret
metadata:
annotations:
networking.istio.io/cluster: cluster2
creationTimestamp: null
labels:
istio/multiCluster: "true"
name: istio-remote-secret-cluster2
namespace: istio-system
stringData:
cluster2: |
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: {CERTIFICATE}
server: {CLUSTER2-APISERVER-ADDRESS}
name: cluster2
contexts:
- context:
cluster: cluster2
user: cluster2
name: cluster2
current-context: cluster2
kind: Config
preferences: {}
users:
- name: cluster2
user:
token: {TOKEN}The key role of this Secret is to enable Istio in the primary cluster (cluster1) to access the API server of the remote cluster, thereby obtaining service information. Additionally, in the remote cluster (cluster2), the Istiod service points to the primary cluster’s Istiod service’s LoadBalancer IP (ports 15012 and 15017), allowing cluster2 to communicate with the primary cluster’s Istiod.
Visualizing Authentication
Since both clusters share a CA (provided by the primary cluster) and the remote cluster can access its own API server, the Istiod in the primary cluster can validate requests from the remote cluster (cluster2). The following sequence diagram clearly shows this process:
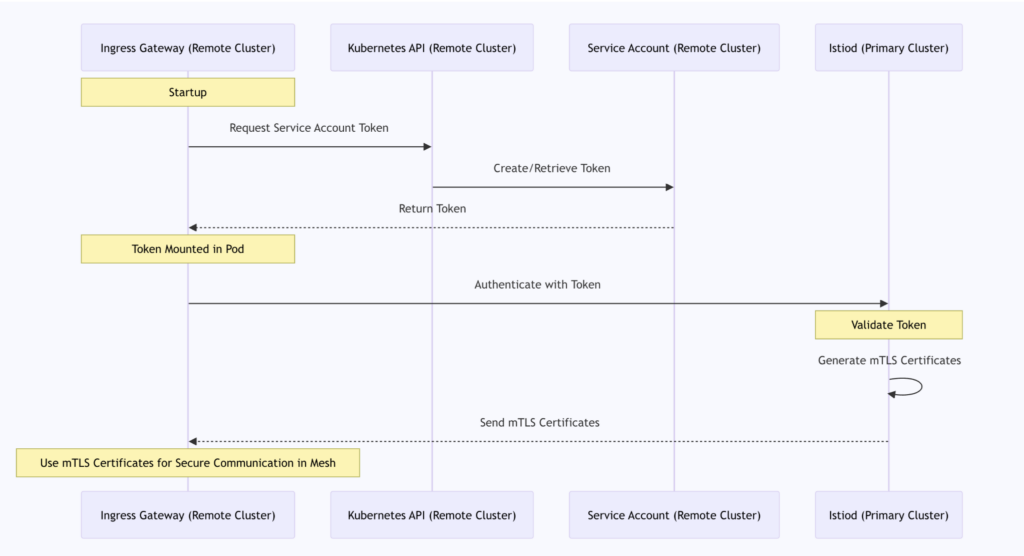
This process is a key component of Istio’s multi-cluster configuration, ensuring secure cross-cluster communication within the service mesh. As seen in this discussion, both the remote gateway and the services depend on the primary cluster’s CA for initial mTLS authentication, providing a solid foundation for secure communication across the entire service mesh.
Conclusion
In this blog, we explored how the gateway in a remote cluster initially authenticates to an external Istiod in Istio’s primary-remote deployment. We explained how to create a Secret containing a kubeconfig to allow Istio in the primary cluster to access the remote cluster’s API and how shared CA and service account tokens ensure the security of mTLS authentication. This process secures cross-cluster communication within the service mesh, providing key insights for understanding and implementing Istio’s multi-cluster configuration.
###
If you’re new to service mesh, Tetrate has a bunch of free online courses available at Tetrate Academy that will quickly get you up to speed with Istio and Envoy.
Are you using Kubernetes? Tetrate Enterprise Gateway for Envoy (TEG) is the easiest way to get started with Envoy Gateway for production use cases. Get the power of Envoy Proxy in an easy-to-consume package managed by the Kubernetes Gateway API. Learn more ›
Getting started with Istio? If you’re looking for the surest way to get to production with Istio, check out Tetrate Istio Subscription. Tetrate Istio Subscription has everything you need to run Istio and Envoy in highly regulated and mission-critical production environments. It includes Tetrate Istio Distro, a 100% upstream distribution of Istio and Envoy that is FIPS-verified and FedRAMP ready. For teams requiring open source Istio and Envoy without proprietary vendor dependencies, Tetrate offers the ONLY 100% upstream Istio enterprise support offering.
Get a Demo